Interframe Compression Techniques
Interframe compression is compression applied to a sequence of video frames, rather than a single image. In general, relatively little changes from one video frame to the next. Interframe compression exploits the similarities between successive frames, known as temporal redundancy, to reduce the volume of data required to describe the sequence.
There are several interframe compression techniques, of various degrees of complexity, most of which attempt to more efficiently describe the sequence by reusing parts of frames the receiver already has, in order to construct new frames.
Sub-sampling
Sub-sampling can also be applied to video as an interframe compression technique, by transmitting only some of the frames. Sub-sampled digital video might, for example, contain only every second frame. Either the viewer’s brain or the decoder would be required to interpolate the missing frames at the receiving end.
Difference Coding
Difference coding, or conditional replenishment, is a very simple interframe compression process during which each frame of a sequence is compared with its predecessor and only pixels that have changed are updated. In this way only a fraction of the number of pixel values is transmitted. The images below are successive frames from the table tennis sequence and illustrates how, frequently, very little changes from one frame to the next.


Consecutive frames from the Table Tennis sequence.
If the coding is required to be lossless then every changed pixel must be updated. There is an overhead associated with indicating which pixels are to be updated, and if the number of pixels to be updated is large, then this overhead can adversely affect compression.
Two modifications can alleviate this problem somewhat, but at the cost of introducing some loss. Firstly, the intensity of many pixels will change only slightly and when coding is allowed to be lossy, only pixels that change significantly need be updated. Thus, not every changed pixel will be updated. Secondly, difference coding need not operate only at the pixel level, but at the block level.
Block Based Difference Coding
If the frames are divided into non-overlapping blocks and each block is compared with its counterpart in the previous frame, then only blocks that change significantly need be updated. If, for example, only those blocks of the Table Tennis frame that contain the ball, lower arm and bat were updated, the resulting image might be an acceptable substitute for the original.
Updating whole blocks of pixels at once reduces the overhead required to specify where updates take place. The 160x120 pixels in the Table Tennis frame can be split into 300 8x8 pixel blocks. Significantly fewer bits are required to address one of 300 blocks than one of 19200 individual pixels. If pixels are updated in blocks, however, some pixels will be updated unnecessarily, especially if large blocks are used. Also, in parts of the image where updated blocks border parts of the image that have not been updated, discontinuities might be visible and this problem is worse when larger blocks are used. Clearly the choice of block size must be an informed one so as to achieve the best balance between image quality and compression.
Block Based Difference Coding can be further improved upon by compensating for the motion between frames. Difference Coding, no matter how sophisticated, is almost useless where there is a lot of motion. Only objects that remain stationary within the image can be effectively coded. If there is a lot of motion or indeed if the camera itself is moving, then very few pixels will remain unchanged. Even a very slow pan of a still scene will have too many changes to allow difference coding to be effective, even though much of the image content remains from frame to frame. To solve this problem it is necessary to compensate in some way for object motion.
Block Based Motion Compensation
Block based motion compensation, like other interframe compression techniques, produces an approximation of a frame by reusing data contained in the frame's predecessor. This is completed in three stages.
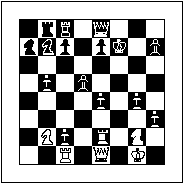
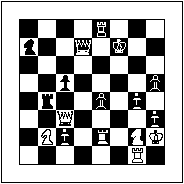
Past Frame - Current frame to be coded
First, the frame to be approximated, the current frame, is divided into uniform non-overlapping blocks, as illustrated below (left).
Then each block in the current frame is compared to areas of similar size from the preceding or past frame in order to find an area that is similar. A block from the current frame for which a similar area is sought is known as a target block.
The location of the similar or matching block in the past frame might be different from the location of the target block in the current frame. The relative difference in locations is known as the motion vector. If the target block and matching block are found at the same location in their respective frames then the motion vector that describes their difference is known as a zero vector. The illustration below shows the motion vectors that describe where blocks in the current frame (below left) can be found in past frame (above left).

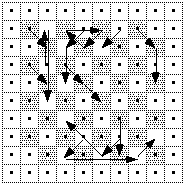
Current frame to be coded divided into blocks. Motion vectors indicating where changed blocks in the current frame have come from. Unchanged blocks are marked by dots.
Finally, when coding each block of the predicted frame, the motion vector detailing the position (in the past frame) of the target block’s match is encoded in place of the target block itself. Because fewer bits are required to code a motion vector than to code actual blocks, compression is achieved.
During decompression, the decoder uses the motion vectors to find the matching blocks in the past frame (which it has already received) and copies the matching blocks from the past frame into the appropriate positions in the approximation of the current frame, thus reconstructing the image. In the example used above, a perfect replica of the coded image can be reconstructed after decompression. In general this is not possible with block based motion compensation and thus the technique is lossy.
The effectiveness of compression techniques that use block based motion compensation depends on the extent to which the following assumptions hold.
- Objects move in a plane that is parallel to the camera plane. Thus the effects of zoom and object rotation are not considered, although tracking in the plane parallel to object motion is.
- Illumination is spatially and temporally uniform. That is, the level of lighting is constant throughout the image and does not change over time.
- Occlusion of one object by another, and uncovered background are not considered.
Bidirectional motion compensation uses matching blocks from both a past frame and a
future frame to code the current frame. A future frame is a frame that is displayed after the current frame. Considering the chess board example, suppose that a player is fortunate enough to have a once lost queen replace a pawn on the board. If the queen does not appear on the board before the current move then no block containing the queen can be copied from the previous state of play and used to describe the current state. After the next move, however, the queen might be on the board. If in addition to the state of play immediately before the current move, the state of play immediately following is also available to the receiver, then the current image of the chess board can be reproduced by taking blocks from both the past and future frames.
Bidirectional compression is much more successful than compression that uses only a single past frame, because information that is not to be found in the past frame might be found in the future frame. This allows more blocks to be replaced by motion vectors. Bi-directional motion compensation, however, requires that frames be encoded and transmitted in a different order from which they will be displayed.
Motion Compensated Video Compression Overview
© Colin E. Manning 1996 Main Digital Video Page